
- By André Guelfi Torres
- ·
- Posted 16 Apr 2019
Snapshot testing compares a "snapshot" of the output of a prior version of your software to output from the latest version, to check for unintended changes. When a difference is found you either approve it, by updating the expected output snapshot, or fix the cause of the difference.
Visual regression testing is a form of snapshot testing that tests a web front-end. It goes beyond testing the markup or layout by testing the rendered page captured in an emulated browser. As such they can "catch CSS Curve Balls" as BackstopJS says.
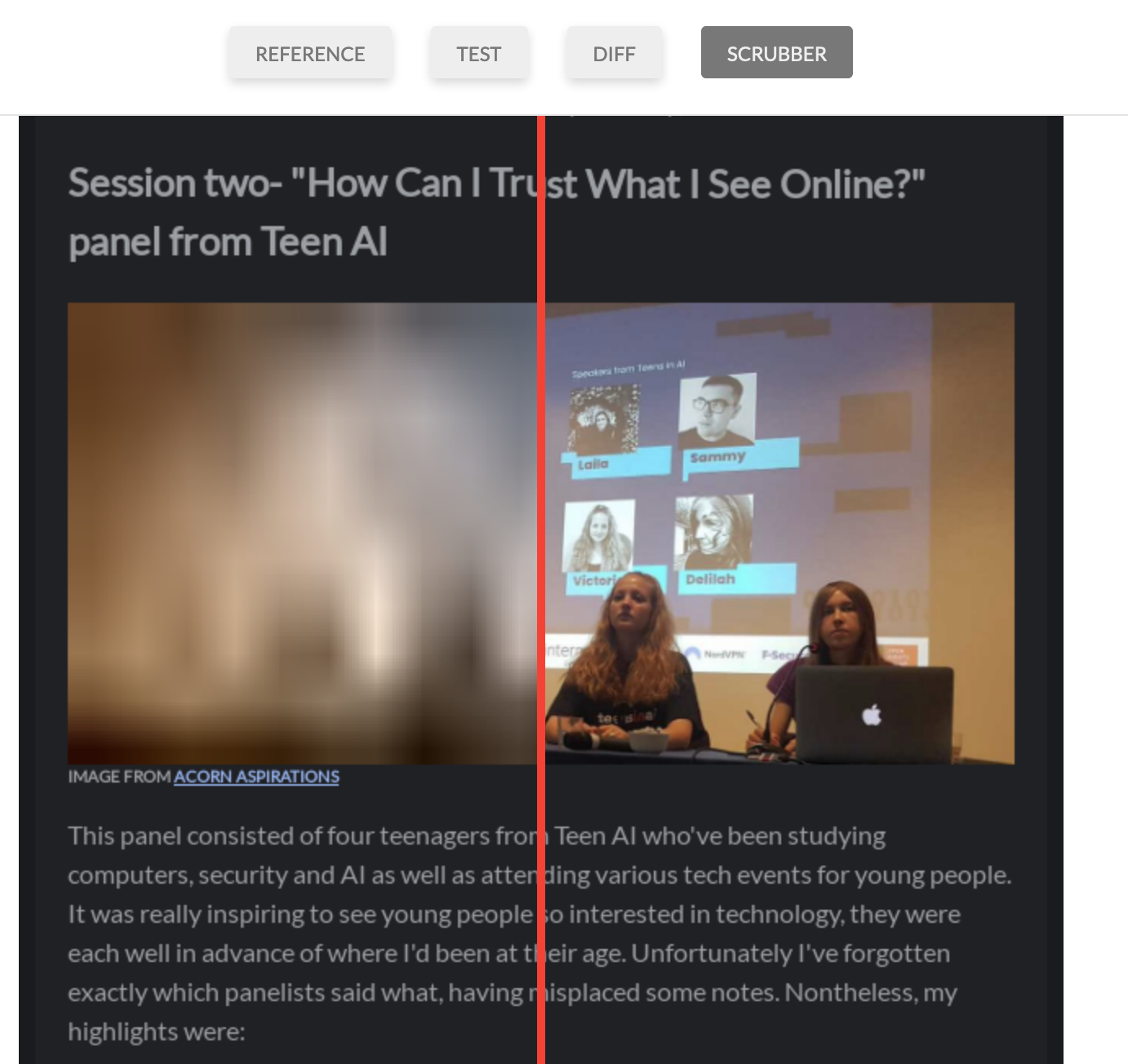
BackstopJS is a framework for visual regression testing, written in Javascript. It treats your web service as a black box, so your website doesn't need to be written in Javascript to work with BackstopJS. One of the benefits it offers is a very comprehensive and helpful diff between your snapshots, embedded in a HTML report that it generates. An example below shows how the scrubber diff method allows you to see both test and reference snapshots simultaneously. You can move the red line to change where the boundry lies.
This article will explain how to set up BackstopJS and some good practices I've picked up from using it in anger. You'll need to have some awareness of Docker Compose and Yarn or NPM.
Why use visual regression testing? I'll assume that you appreciate why testing as a general practice is necessary, so here are several scenarios that visual regression tests will catch and other testing techniques won't:
Setting up BackstopJS isn't difficult. But I'm going to make it more difficult because we want to set it up in a way that's repeatable (ie it always has the same result for the same version of the software) and automated. You don't want your visual regression tests to be "flaky", to pass some times and not others. It's worth putting extra effort in to get this right, otherwise they may be less than useful. And you want them to be automated because that way you can trust yourself and others not to forget to run the test or update the snapshots, and you can use them as checks for Dependabot's auto-merge.
Ultimately, your workflow should look like:
The first step to creating a repeatable visual regression test is to run the tests on the same platform every time. Otherwise, you're in for trouble. Small changes in things like font rendering between operating systems can prevent the reference snapshots generated on your local machine from matching the test snapshots generated on your CI server. And if your CI server has multiple test runners on different platforms you've got even more unpredictability on your hands. To get around issues like these we use Docker containers via Docker Compose. This guaruntees the same platform for every test run. This approach also has the advantage that you don't need to install BackstopJS locally and end up with different versions of it on each developer's machine; instead you have one consistent version, and Dependabot can keep it up-to-date. The disadvantage is of course that it's slower.
Add the following entry to your root docker-compose.yml (create one if necessary):
visual_regression_tests:
image: backstopjs/backstopjs:4.4.2
volumes:
- ./test/visual:/src
This describes a visual_regression_tests Docker container using the official backstopjs image, version 4.4.2. The version can be left out, but it's important that it be there for repeatability. You can use Dependabot to keep it up-to-date by creating a Dockerfile for it (until Dependabot adds Docker Compose support), which is described below. Of course, you should copy the latest version number from the BackstopJS Docker image releases and use that; 4.4.2 may be outdated at time of reading. If you're using a Docker container for your website as well you should add a depends_on entry to that container.
The last part is the key; the volume configuration ./test/visual:/src. This maps the local relative path ./test/visual to /src in the container. You may change ./test/visual to any relative path you like, but /src must be constant because that is where BackstopJS will look inside the container for it's configuration.
Previously, I said that with Docker developers don't need to install a local instance of BackstopJS on their machines. This is true, but with one exception: You. That's because for our next step we're going to create the BackstopJS configuration, and you'll need to use Backstop to create a default instance of the configuration. So try this:
yarn global add backstopjs
mkdir ./test/visual
cd ./test/visual
backstop init
First we install BackstopJS (NPM alternative: npm install -g backstopjs) and then create the folder where our container expects to find the configuration (so change this as you like, but ensure it's consistent with the Docker Compose volume). Then we open the folder and initialise a BackstopJS config there. This creates a few files; backstop.json, and backstop_data/engine_scripts. The engine scripts are basic defaults that determine how to run the browser emulator. Unless you're doing something unusual you shouldn't need to change most of them.
Before going any further, create a .gitignore in your BackstopJS folder with the following entries:
backstop_data/bitmaps_test
backstop_data/html_report
This will ensure that the test snapshots and HTML reports generated by Backstop are ignored by Git. You don't want to commit these to version control, but you do want to commit the other folder it generates; the snapshot references to test against.
The backstop.json file is your main means of interacting with BackstopJS and to start with should look something like this:
{
"id": "backstop_default",
"viewports": [
{
"label": "phone",
"width": 320,
"height": 480
}
…
],
"onBeforeScript": "puppet/onBefore.js",
"onReadyScript": "puppet/onReady.js",
"scenarios": [
{
"label": "BackstopJS Homepage",
"cookiePath": "backstop_data/engine_scripts/cookies.json",
"url": "https://garris.github.io/BackstopJS/",
"referenceUrl": "",
"readyEvent": "",
"readySelector": "",
"delay": 0,
"hideSelectors": [],
"removeSelectors": [],
"hoverSelector": "",
"clickSelector": "",
"postInteractionWait": 0,
"selectors": [],
"selectorExpansion": true,
"expect": 0,
"misMatchThreshold" : 0.1,
"requireSameDimensions": true
}
],
"paths": {
"bitmaps_reference": "backstop_data/bitmaps_reference",
"bitmaps_test": "backstop_data/bitmaps_test",
"engine_scripts": "backstop_data/engine_scripts",
"html_report": "backstop_data/html_report",
"ci_report": "backstop_data/ci_report"
},
…
}
The first thing I'd advise changing is the viewports property. This property determines the resolutions that the site will be tested at. The default is not very extensive, and in my current team we've settled on the following viewport configuration:
"viewports": [
{
"label": "small",
"width": 640,
"height": 480
},
{
"label": "medium",
"width": 814,
"height": 768
},
{
"label": "large",
"width": 1066,
"height": 814
},
{
"label": "xlarge",
"width": 1400,
"height": 1050
},
{
"label": "xxlarge",
"width": 1600,
"height": 1200
}
]
The next interesting property is scenarios. A scenario defines a test, and you'll want to add one for each major section of your website. With a blog for example you may want to test the blog page and the blog list page, so you would have two scenarios.
The real trick here that will lead you to either jubilation or despair is figuring out when to take the snapshot. Browsers, Javascript, web services and HTTP are all such fickle beasts; they may load slightly faster or slower each time you create a snapshot. For your visual regression tests to be repeatable you need them to create the snapshot only when the page has finished loading. If you don't you'll find many test failures caused because the font hadn't loaded in yet, or a pop-up hasn't appeared yet, or a HTTP request to an AJAX dependency hadn't completed yet, et cetra. As such a lot of the scenario configuration options are about when to decide that the page has finished loading. This is the real meat of the configuration and each possible option is documented in BackstopJS's readme, but a few key ones to highlight are:
cookiePath: This enables you to enter faked cookies into the browser emulator, this can be useful to send a token to an authenticated web service. Just set it to a relative path to a JSON file; the expected format is described in a sample file, engine_scripts/cookies.json.url: This is the full address of the web page being tested. If you're using a Docker container to host your site you may use the name of the container, like http://website:8080/myPage. Otherwise, you may run it locally and use something like http://localhost:8080/myPage.readyEvent: Listen out for a console log telling you the page is fully loaded before starting. This is useful for repeatability.readySelector: Similar to the above, this configures Backstop to wait until a particular element (defined by CSS selector) is appearing before starting. I recommend using this setting and setting it to something that won't appear on any of your error pages. If your service doesn't work during a visual regression test you may not know until after you get the report and are staring at a diff between your reference and a 404 page. But if your readySelector fails you get a timeout error in the output that lets you know that the expected page hasn't loaded, so you get the feedback sooner.delay: Avoid using this setting if you can. It allows you to set an arbitrary time to wait for the page to load before assuming it'll be ready to test. By default it is 0, which means no delay. If you find yourself using this setting, it's because you haven't found a reliable method to tell the browser that the page is loaded. You should only use this as an absolute last resort.hideSelectors/removeSelectors: If you have some problematic element on the page that you either can't rely on to load in a reliable, timely fashion, or which has some random element that changes each time it's loaded then you can hide those elements using either of these properties.scrollToSelector: BackstopJS will capture the entire document, not just the visible section (unless configured otherwise). However, you may want to trigger some event via scrolling. This setting makes Backstop scroll to a particular selector.selectors: By default BackstopJS will capture the entire document. But if you want to test a specific set of regions, you can use this to limit the elements used to generate the snapshot. It's the opposite of hideSelectors/removeSelectors (but they can be used together). It's especially useful when you want to break a complex page down into smaller parts; you'll get more specific feedback on individual components, making regressions easier to identify.misMatchThreshold: The degree to which two snapshots must be different before the scenario fails. This defaults to 0.1 (That's 0.1%, not 10%) and I wouldn't increase it without good reason.At this point you should be able to run your tests. From the root of the project do docker-compse run visual_regression_tests reference; this will generate your first reference images. Then try docker-compose run visual_regression_tests test; this will generate new references and test them against the last ones you captured. I suggest recording these commands as scripts, so that every developer doesn't have to remember them. In Yarn/NPM we add a script to package.json for run these commands, otherwise we create a shell script inside a ./scripts folder.
Don't worry if your tests aren't passing the first time; I'll explain some ways that you can improve their consistency and reliabiliy.
Just in case I haven't said this enough times: Repeatability is key. One of the obstacles to this repeatability is ensuring that your dependencies are consistent. If you depend on a web service or a database that sends you some data to display on the page, then that service needs to send the same data every time the visual regression tests are run. This means that you need the capability to fake your dependencies. If you depend on a database, then you may want to achieve this by creating a Docker container of your particular database dependency with some minimal fake data. If you're dependent on web services, then I'd recommend using Mockingjay Server. It's a Docker container around the mocking service Mockingjay. This makes for a painless and platform agnostic way to fake your dependencies with web services that respond with fake data. Just add something like the following to your docker-compose.yml:
fake_my_service:
image: quii/mockingjay-server:1.10.4
volumes:
- ./test/fakes:/fakes
command: -config=/fakes/my_service.yaml -port=9099
ports:
- "9099:9099"
For this to work you have to have a directory, here specified as ./test/fakes, with a YML file that specifies the endpoints to fake following Mockingjay-Server's format. This may include multiple fakes for different services. We specify which fake file to use in the command property. Then, we just configure our web service to talk to this fake service when the tests are run. This way we know that our service will reliably, repeatably generate the same output and that's a huge benefit to our testing.
Downloading a non-default font from some server somewhere will take an unpredictable amount of time, so it harms our repeatability. Rather than reaching for that unreliable delay setting, however, we can pre-install the fonts on the Docker image to get around this problem altogether. Simply create a Dockerfile inside your BackstopJS directory with an entry like the following:
FROM backstopjs/backstopjs:4.4.2
RUN apt-get update && apt-get install -y fonts-lato
RUN apt-get update && apt-get install -y fonts-font-awesome
This is a very basic Dockerfile that extends the official BackstopJS image (remember to include the version!) and uses apt-get to install the requisite fonts. This way the browser emulator won't need to download the fonts as they're already installed. You should be able to find the package name of any font you need by searching Debian's package registry. Then you just need to change your docker-compose entry to build your BackstopJS directory, like so:
visual_regression_tests:
image: build: ./tests/visual
volumes:
- ./test/visual:/src
You'll want to add a step to your build to run the visual regression tests. If you created a script to run the tests earlier then you can simply plug it in here. Because we're using Docker you needn't install BackstopJS on your CI server, and it will play nicely with Docker-based CI systems like CircleCI. There is an important extra step though; you need to extract the build artifact from BackstopJS. Otherwise, you won't be able to see why your tests have failed.
For Jenkins you can achieve this with the HTML Publisher Plugin. Though the official jenkins support guide involves setting up a Jenkins job in the traditional web interface, I'd advise against that and use the declarative Jenkinsfile method. If you already have a declarative Jenkinsfile just add something like the following to your always post-step in your Jenkinsfile:
post {
always {
publishHTML(target: [
allowMissing: false,
alwaysLinkToLastBuild: true,
keepAll: true,
reportDir: './test/visual/backstop_data',
reportFiles: 'html_report/index.html',
reportName: 'Visual Regression Tests Report'
])
}
}
Lastly, to ensure repeatability you can actually repeat the tests. When first setting up any tests involving browser emulation or browser automation I won't accept a passing test as correct unless it passes many times, so I can be confident that it isn't going to prove unreliable ("flaky") in the future. A simple Bash script like the following will suffice:
set -e #ensures the script will halt if any of the test runs fail
for i in {0..19}; do
yarn test:visual
done
Sure, it may take a while to run. Just leave it running in the background while you're doing something else.
There are a number of other approaches to running BackstopJS, but this is the best type of setup I've found. Hopefully I've equipped you with everything you'll need to get up and running with repeatable BackstopJS visual regression tests on your websites. Let me know how you get on.


Software is our passion.
We are software craftspeople. We build well-crafted software for our clients, we help developers to get better at their craft through training, coaching and mentoring, and we help companies get better at delivering software.