
- By Matt Belcher
- ·
- Posted 09 Jun 2020
I think we can all agree that we want our software delivery teams to be successful. Being “successful” generally boils down to two things: speed and stability. Organisations want their software delivery teams to be able to build and deliver products quickly so they can be in the hands of their customers sooner and enable the organisation to better react to the demands of the marketplace. Organisations also want a high degree of confidence in the outputs being produced by their software delivery teams. Broken, buggy or incorrect software will cause customers to be unhappy and likely damage the organisation’s reputation and/or lead to financial loss. Typically this balance between stability and speed has been seen as a trade-off teams had to make: teams either go slow and steady and build quality products or rush, cut corners and likely introduce some bugs and errors along the way.
However, the company DORA (DevOps Research and Assessment), founded by Dr. Nicole Forsgren, Jez Humble and Gene Kim argue that it doesn’t have to be a trade-off: it is possible to build stable software at speed. They have data to back this up too - lots of it. Through their work researching and analysing how many different software delivery teams operate, they have collected a wealth of data on different organisations and have performed detailed analysis across that data. What they found is rather interesting indeed. They discovered that the best performing software teams all performed highly across four metrics: Deployment Frequency, Change Failure Rate, Mean Time To Recover (MTTR), Lead Time.
Simply put - how often is your team deploying into the production environment? The more often changes are deployed to production and put into the hands of your customers then the tighter the feedback loop is between you and your customer. A high deployment frequency also means that you are delivering value to your customers at a faster rate.
It’s all well and good deploying your software to production frequently, but if these deployments result in breaking changes being introduced that impact your customer’s ability to use your product then that’s not good at all. We want to be deploying new changes into production regularly but not at the cost of quality. Change Failure Rate is a measure of how often a deployment to production results in a failure of some kind being introduced.
Building on top of Change Failure Rate, if a team does introduce a failure into the system through a new deployment to production then it’s key the team is able to both detect it quickly and get the system back into a fully working state again. MTTR is a measure of this - how long does it take for a team to notice that a regression has been introduced into the production environment, to understand it and then get the system back into a healthy state again. Ultimately for teams to do well here they need to invest in good monitoring and observability. Having logs automatically shipped to a central repository where they can be easily queried is becoming more and more important. Many teams use this to then build dashboards to reflect the health of their application and related infrastructure and also to then set up automated alerting.
Lead time is a measure of the time taken between a code change being committed to the version control repository right up until that change is successfully running in production. Analysing lead time allows teams to look at their whole delivery system and understand where the bottlenecks / slowest parts are. Once teams have an understanding of their lead time it can be a powerful tool not only for identifying parts of the delivery system that require optimising but it can also play a key role in decision making both within the team and across the wider organisation as it can help to provide answers to questions such as “If we start work on this today when can we get it to production?” or “Can this feature be delivered in time?”
These four metrics have been found to be a strong indicator of successful software delivery teams. The State of DevOps reports reported that teams which scored highly across these metrics tended to perform the best. Whilst teams which scored poorly tended to perform less well, as outlined in the table below :
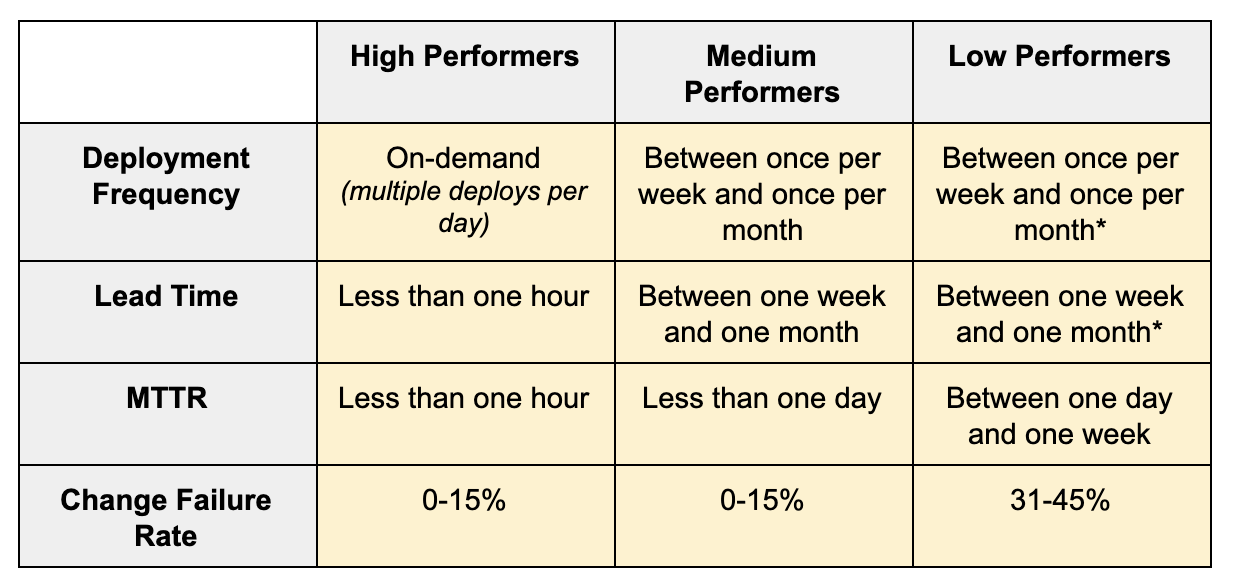
The 4 metrics work well together because following them enforces teams to adopt good technical practices which build upon and reinforce one another. For example to be able to deploy software frequently, automation of the deployment process is required. Which means that there is a repeatable process which is documented in code and not solely reliable on manual effort. To have a low change failure rate, teams need to adopt testing. But if this testing is entirely manual then it will impact the team’s ability to deploy to the production environment frequently. Therefore, the bulk of this testing needs to be automated. To have a good measure of MTTR, teams need to invest in alerting, monitoring and observability. This enables them to have a good understanding of what their software is doing in production, how it is being used by the customers and more importantly be alerted in the case of failures. Not only that though, but it also encourages teams to focus on their “Path to Production.” MTTR is not just about being able to detect when a failure has occurred and understand it, it’s also about remedying the situation. To be able to remedy failure in production quickly, teams need to have a reliable “Path to Production” - a well established route for getting their software into the production environment and having confidence in that. Finally, for teams to achieve a good lead time measure, it requires automation around testing, packaging, deployment. Work should flow through the team seamlessly and any blockers that arise get addressed quickly and are resolved. It is the coming together of these good practices that ultimately allows teams to go fast but still have a good level of stability. They allow for quality to be ‘baked in’ and create fast feedback mechanisms.
I would recommend that your teams invest time to understand these four metrics and start capturing them. From my experience, I would not recommend teams look for absolute values across any of these four metrics. Instead, start off with creating baseline measures across all four. This will give you an insight into how your team is performing today and likely areas for improvement. Setup mechanisms for regularly measuring these four metrics and ideally have the process automated. Regularly check on how your team is performing across each metric. The key thing to look for is trend - i.e. is your team’s performance across each metric getting better?
Overall, having a handle on each of the four metrics discussed in this article will not only provide you with a well-rounded picture of how your team is performing, but it will also provide you with insights into where your teams can improve and what may be holding you back. It also provides a very useful feedback mechanism when introducing changes in the team. Striving to improve across each of the four metrics will ensure that your software delivery team moves in the direction to be able to deliver quality products at speed.


Software is our passion.
We are software craftspeople. We build well-crafted software for our clients, we help developers to get better at their craft through training, coaching and mentoring, and we help companies get better at delivering software.